Convolutional Neural Networks (CNNs) have revolutionized the field of artificial intelligence, particularly in image and video processing. Their architecture is designed to automatically and adaptively learn spatial hierarchies of features from input images. This comprehensive exploration will delve into the workings of CNNs, their architecture, training processes, applications, and advancements in the field.
1. The Basics of Neural Networks
1.1 What is a Neural Network?
A neural network is a computational model inspired by the way biological neural networks in the human brain process information. It consists of interconnected nodes or neurons arranged in layers. The basic structure includes:
- Input Layer: Receives the initial data.
- Hidden Layers: Intermediate layers where computations occur.
- Output Layer: Produces the final output.
1.2 Activation Functions
Activation functions introduce non-linearity into the model, allowing neural networks to learn complex patterns. Common activation functions include:
- Sigmoid: Outputs values between 0 and 1, commonly used in binary classification.
- ReLU (Rectified Linear Unit): Outputs zero for negative inputs and the input itself for positive values, promoting sparsity.
- Softmax: Converts logits into probabilities for multi-class classification tasks.
2. Introduction to Convolutional Neural Networks
2.1 What is a CNN?
A CNN is a specialized type of neural network designed for processing structured grid data, such as images. Unlike traditional neural networks, CNNs leverage local patterns in data through convolutional layers, making them particularly effective for image recognition tasks.
2.2 Key Features of CNNs
- Parameter Sharing: Reduces the number of parameters, making training faster and less memory-intensive.
- Local Connectivity: Neurons in a convolutional layer are only connected to a small region of the input, capturing local features.
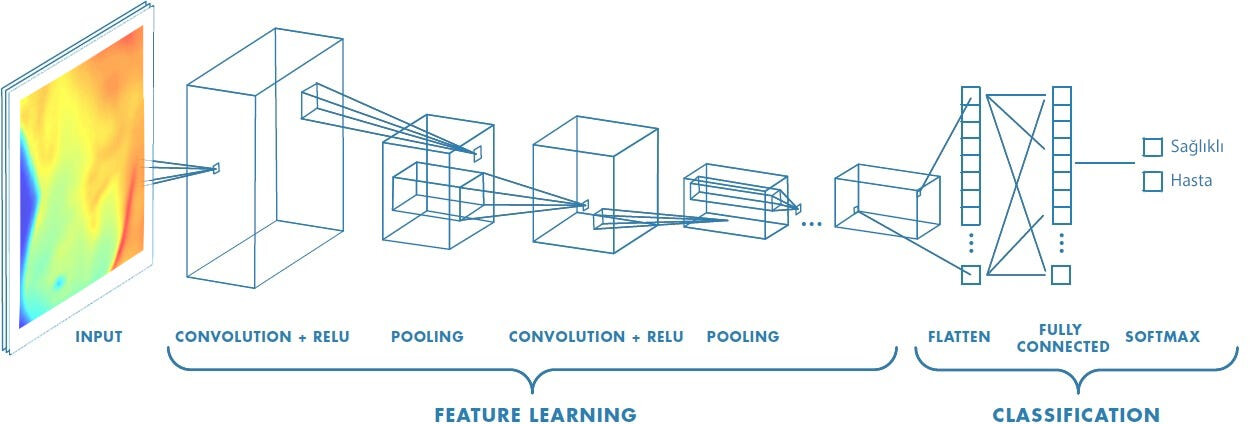
3. CNN Architecture
The architecture of a CNN typically consists of several layers, each serving a specific function. The main components include:
3.1 Convolutional Layers
Convolutional layers are the core building blocks of CNNs. They apply convolution operations on input data using filters (kernels) to extract features.
- Convolution Operation: The filter slides over the input image, computing dot products between the filter and the input patch.
- Stride: The stride determines how much the filter moves across the input. A stride of 1 means the filter moves one pixel at a time, while a stride of 2 skips every other pixel.
- Padding: Padding adds extra pixels around the input to control the spatial dimensions of the output. Common types include:
- Valid Padding: No padding, resulting in a smaller output size.
- Same Padding: Pads the input so the output size matches the input size.
3.2 Activation Layers
After each convolutional operation, an activation function is applied to introduce non-linearity. ReLU is the most commonly used activation function in CNNs.
3.3 Pooling Layers
Pooling layers reduce the spatial dimensions of the feature maps while retaining important information. The most common pooling operation is max pooling.
- Max Pooling: Takes the maximum value from each patch of the feature map, effectively downsampling it.
- Average Pooling: Computes the average value from each patch, used less frequently than max pooling.
3.4 Fully Connected Layers
After several convolutional and pooling layers, the high-level reasoning in the neural network is performed using fully connected layers. These layers connect every neuron in one layer to every neuron in the next layer.
3.5 Output Layer
The output layer produces the final predictions. For classification tasks, the softmax activation function is often used to convert logits into probabilities.
4. Training a CNN
4.1 Data Preparation
Before training a CNN, data preparation involves:
- Data Collection: Gathering a diverse dataset for training.
- Data Augmentation: Enhancing the dataset through techniques like rotation, scaling, and flipping to improve model generalization.
- Normalization: Scaling pixel values to a standard range, typically [0, 1] or [-1, 1].
4.2 Forward Propagation
During forward propagation, the input data passes through the network layer by layer. Each layer applies its operations, ultimately producing an output.
4.3 Loss Function
The loss function quantifies the difference between the predicted output and the actual target. Common loss functions for classification tasks include:
- Cross-Entropy Loss: Measures the performance of a classification model whose output is a probability value between 0 and 1.
4.4 Backpropagation
Backpropagation is the process of updating the weights of the network to minimize the loss function. This involves:
- Calculating Gradients: Using the chain rule to compute gradients of the loss with respect to each weight.
- Weight Update: Adjusting the weights using an optimization algorithm, such as Stochastic Gradient Descent (SGD) or Adam.
4.5 Hyperparameter Tuning
Hyperparameters are settings that govern the training process, including:
- Learning Rate: Determines the step size during weight updates.
- Batch Size: The number of training examples used in one iteration.
- Number of Epochs: The number of times the entire training dataset is passed through the network.
5. Applications of CNNs
CNNs have a wide range of applications across various domains, including:
5.1 Image Classification
CNNs excel at image classification tasks, where the goal is to assign a label to an input image. Popular datasets for image classification include:
- CIFAR-10: A dataset with 60,000 32x32 color images in 10 classes.
- ImageNet: A large dataset with over 14 million images across thousands of categories.
5.2 Object Detection
Object detection involves not only classifying objects within an image but also locating them. Techniques like Region-based CNN (R-CNN) and YOLO (You Only Look Once) have been developed for this purpose.
5.3 Semantic Segmentation
Semantic segmentation assigns a class label to each pixel in an image, enabling detailed understanding of the scene. CNNs used for semantic segmentation include architectures like U-Net and SegNet.
5.4 Facial Recognition
CNNs are widely used in facial recognition systems, where they can identify and verify individuals based on facial features.
5.5 Medical Image Analysis
In healthcare, CNNs are employed for diagnosing diseases through medical imaging techniques, such as MRI and CT scans.
6. Advancements in CNNs
6.1 Transfer Learning
Transfer learning involves leveraging pre-trained CNNs on large datasets to improve performance on smaller, domain-specific tasks. This approach reduces training time and resource requirements.
6.2 Fine-Tuning
Fine-tuning is a technique where a pre-trained model is further trained on a new dataset with a lower learning rate, allowing it to adapt to the new task while retaining learned features.
6.3 Data Augmentation Techniques
Advanced data augmentation techniques, such as Generative Adversarial Networks (GANs), are being used to create synthetic training data, enhancing model robustness.
6.4 Architecture Innovations
Innovations in CNN architectures, such as ResNet (Residual Networks) and DenseNet, have introduced new concepts like skip connections and dense connections, improving performance in deeper networks.
6.5 Real-Time Processing
The development of lightweight CNN architectures, like MobileNet and SqueezeNet, enables real-time processing on mobile and embedded devices, expanding the applicability of CNNs.
7. Challenges in CNNs
7.1 Overfitting
Overfitting occurs when a model performs well on the training data but poorly on unseen data. Techniques to mitigate overfitting include:
- Dropout: Randomly deactivating neurons during training to prevent co-adaptation.
- Regularization: Adding a penalty term to the loss function to discourage overly complex models.
7.2 Computational Resources
Training deep CNNs can be resource-intensive, requiring powerful GPUs and significant memory. Techniques to address this include distributed training and model quantization.
7.3 Interpretability
CNNs are often viewed as “black boxes,” making it challenging to understand their decision-making processes. Research into explainable AI aims to provide insights into how CNNs arrive at their predictions.
7.4 Data Bias
Bias in training data can lead to biased predictions, raising ethical concerns. Ensuring diverse and representative datasets is crucial for building fair and equitable AI models.
Conclusion
Convolutional Neural Networks have transformed the landscape of artificial intelligence, particularly in image and video processing. Their unique architecture allows them to learn hierarchical features effectively, making them suitable for a wide range of applications. As technology continues to advance, CNNs are likely to evolve further, incorporating new techniques and methods that enhance their capabilities and address existing challenges. Understanding the workings of CNNs provides valuable insights into their potential and the future of AI in various domains. The continued exploration of CNNs will undoubtedly lead to exciting innovations and applications in the years to come.